SEO baloney.
I took the redeye from Chicago back to the UK. I had to come through Amsterdam (where there's always a gate change and a delay!).
I really wanted to head straight to my bed at home (which I don't seem to have seen much of again, recently) when I realized that my ClickZ article was due *yesterday* - aaarrrggghhh!
Fortunately, I'd been thinking about some of the stuff I picked up from talking to various people at SES. In particular, those who are interested in a new vendor.
Most of them have picked up some of the jargon and terminology. But it did make me think that we do have our own twist on the way we use certain words and phrases.
In particular, a lot of people ask about "reverse-engineering" a ranking algorithm. Yes, many people do believe that some SEOs have tools and methods to do that.
But for the main part, it's not possible to reverse-engineer an algorithm and recreate it, or something like it, if you don't have all of the components.
One such example I gave in the article is one that I use frequently at conferences. Just a couple of graphics which show a bit more about the underlying principles of hyperlink based ranking algorithms.
The first instance, you can see below shows the assumptions made by a "directed edge" or what we would also refer to as a non reciprocal link.
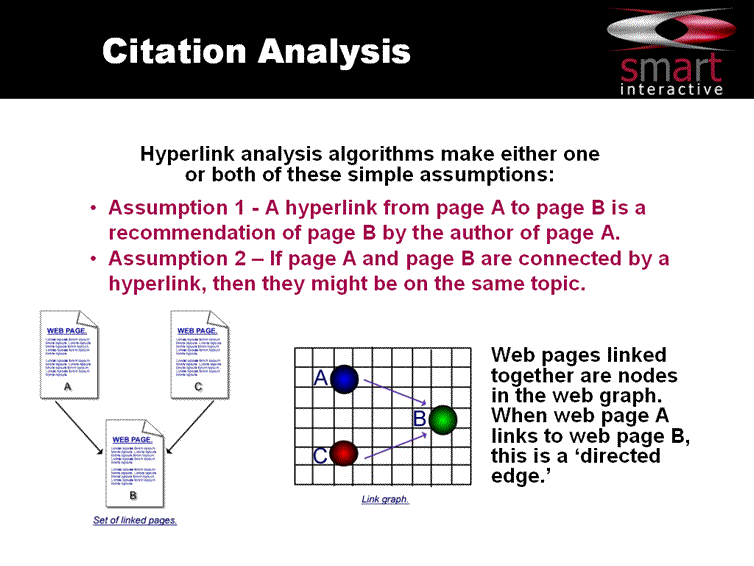 It's not too difficult to get some data on the amount of in-degree (directed edges or inbound links) you have by doing a basic back-link check.
It's not too difficult to get some data on the amount of in-degree (directed edges or inbound links) you have by doing a basic back-link check.
At Google you would simply type into the search box link:www.yourdomainname.com and you'll get back a list of links which point to your site. You can also do this with your competitor's site to see who's linking to him also.
Now, take a look at this graphic below. It looks similar, but what's happening here is that a and b do not link to each other. However, if many other sites link to both a and b, i.e. a pattern emerges where many pages seem to place the two links to those specific pages closely together, even thought a and b don't link together, there's obviously a relationship.
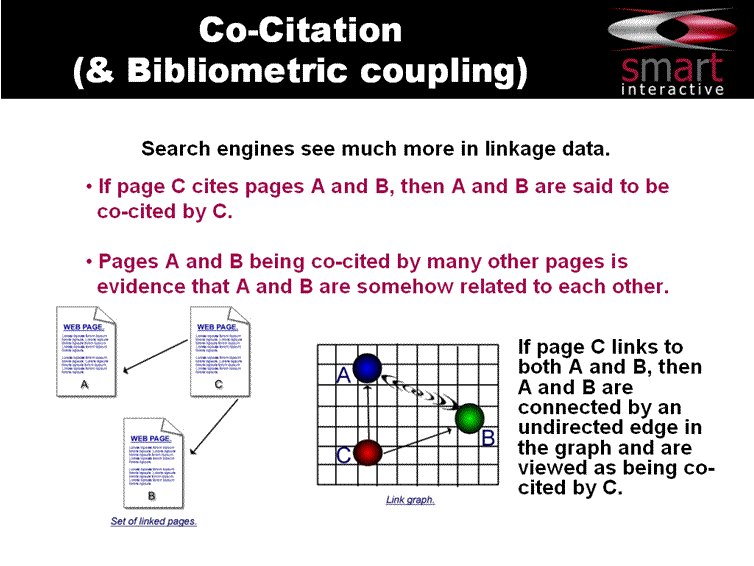 Now the only way to get that information would be to have access to Google's entire database.
Now the only way to get that information would be to have access to Google's entire database.
So, if SEO reverse engineering misses such vital data as co-citation and user behaviour data, then they'll hardly be able to recreate it.
So, what you've got is a list of traces, elements, components and clues to throw around a bit of anecdotal evidence.
Hardly enough to say I've reverse engineered it and I know exactly how it works.
Thank heavens bomb disposal experts understand the full and total requirement of all components to reverse-engineer a detonator. Or there wouldn't be many of them around!
I took the redeye from Chicago back to the UK. I had to come through Amsterdam (where there's always a gate change and a delay!).
I really wanted to head straight to my bed at home (which I don't seem to have seen much of again, recently) when I realized that my ClickZ article was due *yesterday* - aaarrrggghhh!
Fortunately, I'd been thinking about some of the stuff I picked up from talking to various people at SES. In particular, those who are interested in a new vendor.
Most of them have picked up some of the jargon and terminology. But it did make me think that we do have our own twist on the way we use certain words and phrases.
In particular, a lot of people ask about "reverse-engineering" a ranking algorithm. Yes, many people do believe that some SEOs have tools and methods to do that.
But for the main part, it's not possible to reverse-engineer an algorithm and recreate it, or something like it, if you don't have all of the components.
One such example I gave in the article is one that I use frequently at conferences. Just a couple of graphics which show a bit more about the underlying principles of hyperlink based ranking algorithms.
The first instance, you can see below shows the assumptions made by a "directed edge" or what we would also refer to as a non reciprocal link.
It's not too difficult to get some data on the amount of in-degree (directed edges or inbound links) you have by doing a basic back-link check.At Google you would simply type into the search box link:www.yourdomainname.com and you'll get back a list of links which point to your site. You can also do this with your competitor's site to see who's linking to him also.
Now, take a look at this graphic below. It looks similar, but what's happening here is that a and b do not link to each other. However, if many other sites link to both a and b, i.e. a pattern emerges where many pages seem to place the two links to those specific pages closely together, even thought a and b don't link together, there's obviously a relationship.
Now the only way to get that information would be to have access to Google's entire database.So, if SEO reverse engineering misses such vital data as co-citation and user behaviour data, then they'll hardly be able to recreate it.
So, what you've got is a list of traces, elements, components and clues to throw around a bit of anecdotal evidence.
Hardly enough to say I've reverse engineered it and I know exactly how it works.
Thank heavens bomb disposal experts understand the full and total requirement of all components to reverse-engineer a detonator. Or there wouldn't be many of them around!
posted by MikeG @ 6:42 PM
![]()
![]()

6 Comments:
At 5:19 PM, Protheus said…
Protheus said…
Baloney taste's good sometimes ... what do you think of Yahoo's acquisition of Del.icio.us, i think that they are going to be pushing the whole social link modeling much futher and eventually will add this to their algo ...
At 5:43 PM, MikeG said…
MikeG said…
I believe that , once search engines can get a better idea of what pages people actually bookmark or download, that's as strong a vote from the end user on how good it is, as a link from an authority site.
Certainly user behaviour across entire peer groups is going to be heavily factored into algorithms for personalisation.
So, the latest Yahoo! acquisition will help there. But generally speaking, tagging is a good idea anyway. With all of those digital images and music downloads – how are we ever going to find them on our hard drive in five or ten years, if we don't tag them!
At 11:30 PM, Brokerblogger said…
Brokerblogger said…
Hi Mike,
Just in case the ClickZ editors do not let you see my comments to your aritcle on "SEO Jargon", make sure you check out the "Web Economy Bullshit Generator" for a quick laugh = http://www.dack.com/web/bullshit.html
I hope you get to stay home for the holidays.
Bill Kelm
At 10:03 AM, MikeG said…
MikeG said…
Bill,
Bullshit generator - classic!
Thanks for that. And yes, I'll be home for Christmas. But I'll be in Russia for New year!
Have a great holiday yourself.
At 1:57 PM, Protheus said…
Protheus said…
Just to finish with this, i picked this up from the motley fool today Del.icio.us only employs nine people, and the acquisition price is apparently so low as to be unworthy of note when it comes to Yahoo!'s financials.
Looks like yahoo really wants the whole web 2.0 thing and there still are ideas out there instead of everything coming from google
At 12:28 AM, Amanda said…
Amanda said…
Great seeing you again at SES. I don't share your enthusiasm for tagging on a large scale -- folksonomies (hummm)and all of that. For another discussion someday.
Post a Comment
Links to this post:
Create a Link
<< Home